| month | shelver | stacks_books | reference_books | bound_journals | unbound_journals |
|---|---|---|---|---|---|
| 1 | A | 0 | 0 | 337 | 0 |
| 1 | B | 81 | 12 | 0 | 0 |
| 2 | A | 0 | 0 | 325 | 2 |
| 2 | B | 62 | 13 | 0 | 0 |
| 3 | A | 0 | 8 | 258 | 0 |
| 3 | B | 138 | 8 | 5 | 0 |
| 4 | A | 0 | 0 | 72 | 0 |
| 4 | B | 70 | 12 | 0 | 0 |
R Community of Practice
Week 4
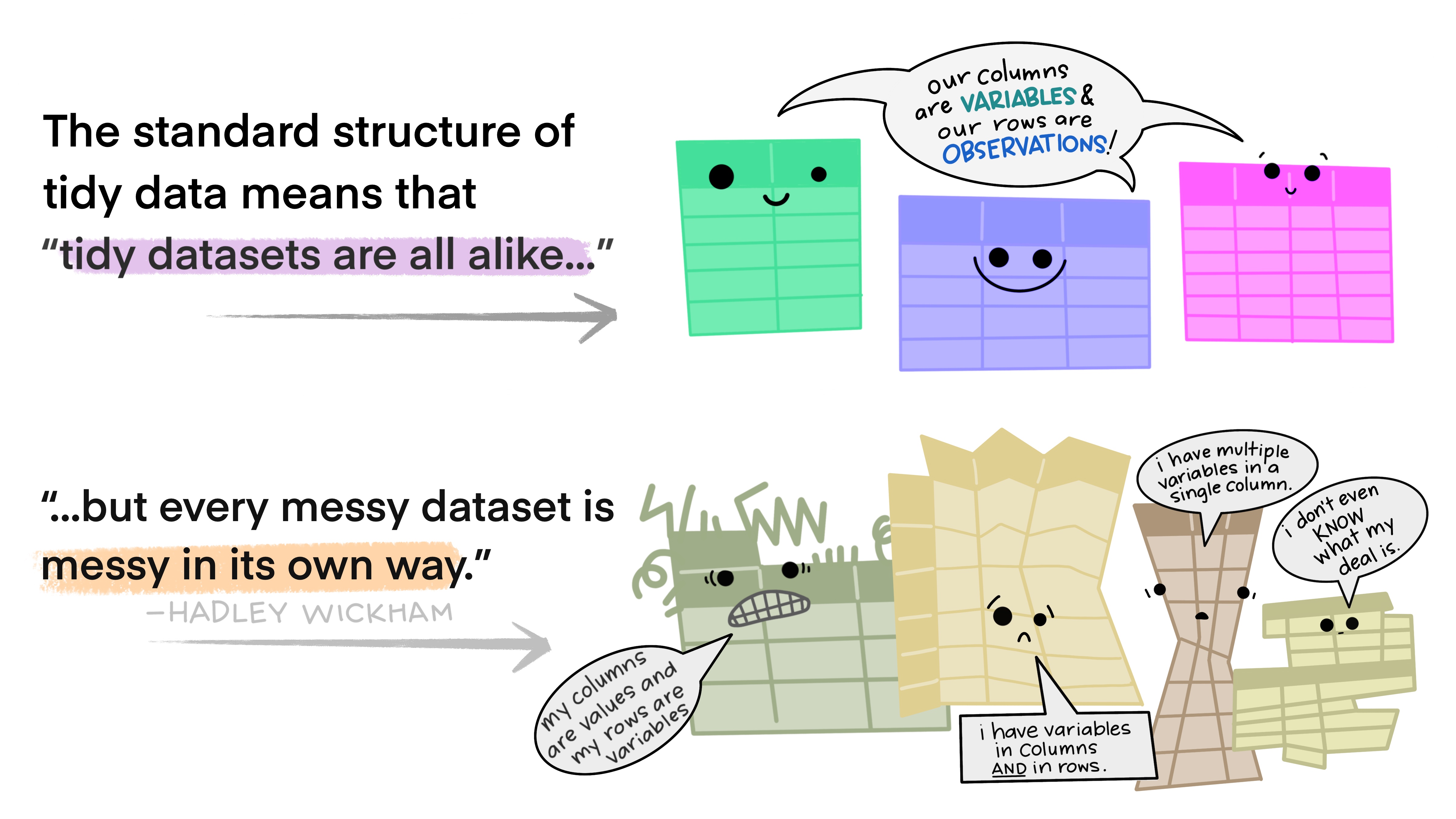
What is Tidy Data 1?

Tidy Data is predictable 1
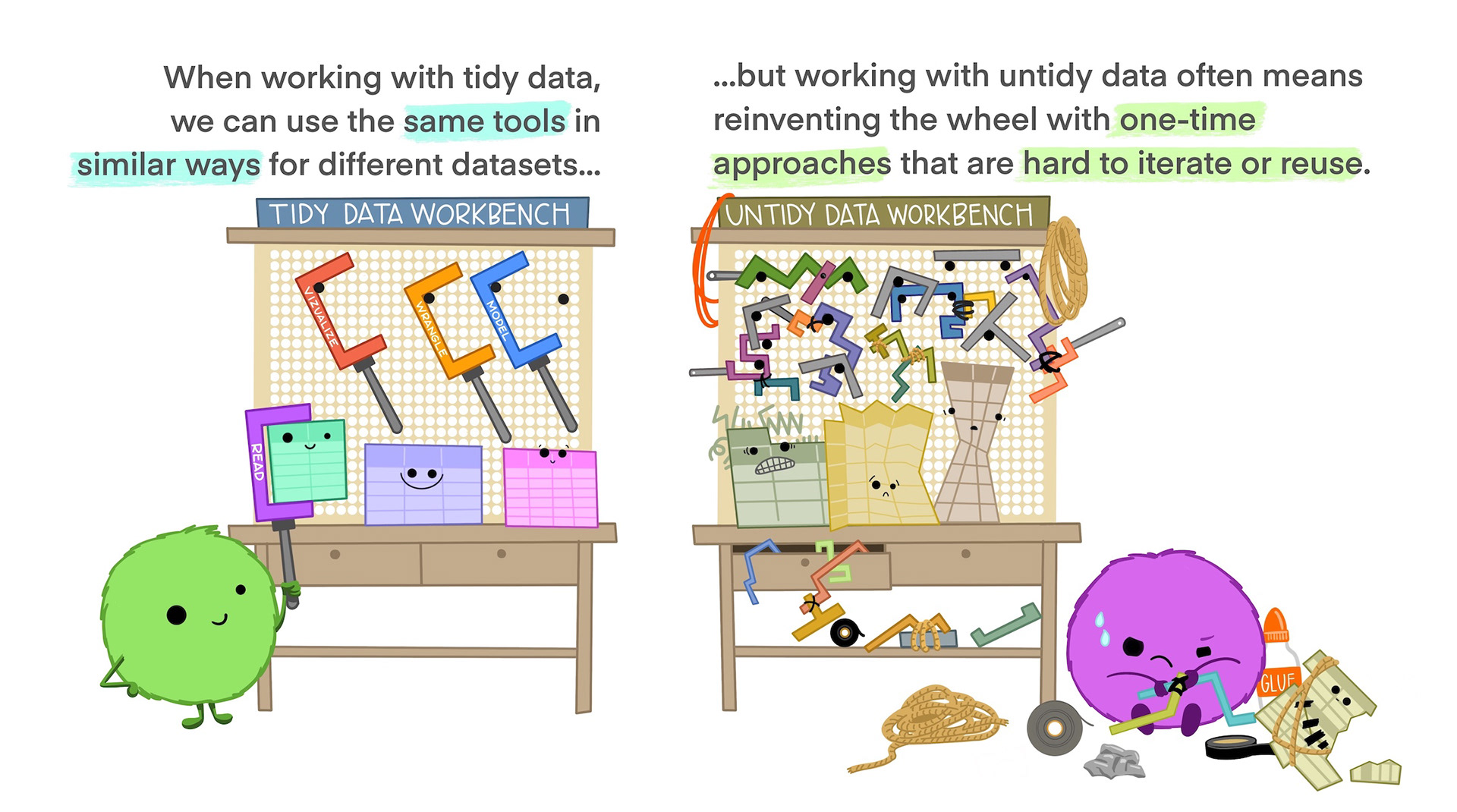
Tidy Data is more efficient 1
pivot_longer()
To lengthen our data, we’ll use the pivot_longer() function from the tidyr package. There are four arguments we need to provide:
data- the data frame to lengthencols- the columns we want to pivot onnames_to- the name of a new column which will have our old column names as valuesvalues_to- the name of a new column which will hold the cell values of the pivoted columns